
Websites come and go. With them, typically goes their data. This is often called “link rot”, when the content in question was also linked to from another source. Sometimes I don’t mind too much, because I’m not terribly invested in that content. However, there are times where content has a relevance in news matters, or as a significant historical timeline.
Sometimes, a website where I contributed content goes away or atrophies– in some form or another — and it makes me sad to see my content go down with the ship.
Three places where I contributed much of my early WordPress content have either lost data, had data corrupted, or disappeared entirely. Each makes me sad.
Some of my earliest WordPress related words were typed out on WP Tavern‘s forums, Theme Hybrid‘s (private) forums, or WPCandy. Each situation is different. WP Tavern’s forums are totally gone, though I’m told there is an offline backup, meaning they could be brought back alive. Theme Hybrid recently deleted all old forum data, though this forum was private and the most excusable of the three in my opinion. (edit: as Sami notes in the comments, the archive was kept. I just didn’t see it.) And WPCandy, while not gone, seems it could disappear any day — and I wrote something like 130-140 blog posts over there. I’d be incredibly sad to see WPCandy disappear forever.
Stories like these aren’t unique to me. All of us that write or comment or participate in online communities have similar stories. It appears that data loss is just a thing we have to live with in the modern age. I know a friend of mine, Siobhan McKeown, has many times struggled with finding old content for the History of WordPress book she is finishing writing.
Fighting link rot
Why is this important and what can we do about it? Well, there are a number of resources that can be helpful.
The first and obvious method for fighting link rot is archive.org, the project that is archiving as much of the web as possible to preserve it for future generations. Archive.org is outstanding, and it is a huge project on a grand scale. The team there makes great efforts to document important websites, and automatically attempts the rest.
The problem is, with many smaller websites it may or may not be successful, or snapshots of the website may be dated or not include everything. Furthermore, if the website isn’t structured in a certain way or is password protected, there’s not much they can do.
So, without relying on archive.org to do it for us, there are two other methods worth noting.
Manual backups
In individual communities, we can manually make the effort to backup sites that we believe are at risk. We should also contact these site owners and requests backups, even if that comes off as an affront.
When Siobhan was writing the History of WordPress book, she was worried that WPCandy could go offline — as it “was becoming particularly degraded” while she was writing — so she personally scraped a backup of the site with a tool called SiteSucker.
SiteSucker finds URLs, logs them, and backs up the source HTML. Similar work can be done with wget, for those that know how to utilize it. It’s my understanding that various individuals have done this with a number of other WordPress websites as well.
For WordPress sites, I know WP Tavern’s forums still exist offline, and Siobhan tells me she even has a backup of the old b2 forums (the software which WordPress was forked from). I’d also guess Justin Tadlock still has a backup somewhere of his forums. I’d love to see these, and other “lost” sites have a public place where the archives can be maintained.
Self-hosted backups
Another method to fight link rot is to backup linked sources as we create new content. Harvard’s Berkman Center is currently beta testing what will be a commercial tool, called Amber, to fight link rot. In the news industry specifically, the source URLs for linked content can contain significant context for a post, making link rot on old posts particularly damaging to the piece that links them, assuming additional context will be available to the reader.
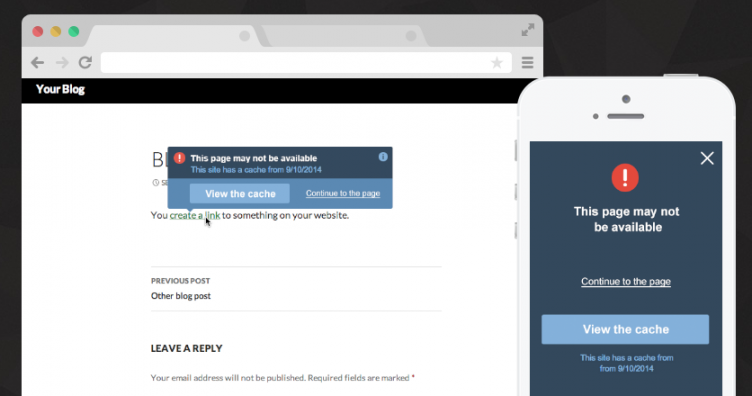
Amber stores the source HTML, much like Archive.org, wget, or SiteSucker, but stores it on the host site’s servers. Meaning, if I were using it here right now, each link in this post would have an associated HTML document on my server to preserve the link and the content therein. The tool then detects 404s if the link rots in the future, and offers up a cached version from my own server.
Obviously a tool like Amber is not a small investment. It would require news organizations to have more server resources at the least, but it would be an important investment to protect the integrity of source content.
The Amber website cites that 49% of links in United States Supreme Court decisions are dead, and that over 135,000 Wikipedia source links are dead. These numbers alone are staggering, and prove a very good point. I can’t imagine what the ratios of dead links are for longstanding newspapers like The New York Times, and others.
Amber will be available for WordPress and Drupal, or most platforms that support Apache or Nginx. I’m really, really excited about this tool. I know it will cost money (in resources at least, as I’m not sure if it’ll be a commercial product), but if enough people adopt it, it could really help save a lot of future data. I’m very interested in it for Post Status, as a number of blogs and companies I cover go away if they are not successful upon launch (when I often cover them).
Why fighting link rot is important
We don’t know what items being published today will be important tomorrow. What we do know is that future politicians, world leaders, and to-be significant individuals and organizations are publishing online today. And when these people or organizations are in significant positions, we will want to know their pasts and opinions.
Perhaps more importantly, cultures, subcultures, and events being documented online may not have any offline version. The web has a beautiful advantage over other mediums like television and newspapers, in that storage of historical data is much simpler, and easier to search. The web enables our timeframe of life on earth to be the most documented in all of human existence.
It is our responsibility as publishers to protect our own content, but also the content of others. I’m reminded how easy it is now because of how hard such efforts are on other mediums. I once read a story about Marion Stokes (also, NPR version), who recorded 35 years of TV news on her own — news that would have been lost without her monumental and perhaps compulsive efforts.
We also have a responsibility as site owners to keep our content up even past when we may hang up our hats. Within our various niche communities, we should be making efforts to document and keep the past.
In the case of WordPress, we’re cataloguing software that powers nearly 25% of the web, and growing. There are important stories being told today that may be educational to future publishers, documentarians, or simply interested individuals. You never know when our content will matter again, but it might, and therefore we should take strides to keep it.



I think Theme Hybrid old forum is still there.
http://themehybrid.com/support/
Dang! I didn’t see that. I just saw Justin’s notes that he deleted it all in the new forum. What he must’ve meant was that he didn’t migrate it, but kept the old install. There you go! I edited the post to reflect it.
I should’ve known Justin wouldn’t have done that. I just checked and I’ve been a member there for 6 years, so that would’ve been a lot of data to lose… Thrilled to see it’s still up.
Isn’t it part of Google’s mission to catalog the entire web? I think I’ve heard that they save everything.
When I first arrived on this page, I saw the huge 404 header image and thought: oh darn, I musta just hit a 404! Kind of made me laugh for a split second. Nice read though: made me think about backing up my own site in ones of these more ‘permanent’ ways… 🙂
Just yesterday I was going through some links to sites I used to read in 2007 / 2008. About 50 / 50 were still live… 🙁
I used to print articles I thought I might need to PDF. I got to the point where I thought that was stupid and switched to bookmarking. Perhaps I should have stuck to PDF! 🙂
What happens if the Internet Archive disappears?
Virtual history goes down the drain along with it 🙁
And here we are going around and telling our children, they should be aware what they write online, because it will remain there forever.